
SuperBatch
Le Gestionnaire de Batch a évolué depuis la version CIVA 2023. L’objectif final reste toutefois le même : lancer à la chaine des simulations prédéfinies issues de n’importe quelle technique disponible dans CIVA. Les principales raisons d’utiliser le Batch sont les suivantes :
- Pas besoin de lancer les calculs manuellement et un par un
- Réduction des temps de calculs grâce à une meilleure exploitation des machines multi-cœurs et à la parallélisation des calculs
- Ajouter à tout moment des simulations dans un Batch déjà lancé
- En cas d’arrêt non souhaité d’un calcul Batch en mode parallélisation, toutes les tâches effectuées sont automatiquement sauvegardées et n’auront pas à être recalculées
Il existe deux modes de calculs Batch :
- Mode « Traditionnel » : pas de parallélisation, les fichiers CIVA sont calculés un par un en suivant la liste de simulations définie
- Mode « Parallélisé » : les fichiers CIVA et les groupes de tâches sont calculés en parallèle
Mode traditionnel
La définition d’un calcul batch en mode traditionnel se déroule en trois étapes (voir l’image ci-dessous) :
- Charger les simulations prédéfinies à traiter
- Garder les paramètres de calcul par défaut : « Nombre d’exécuteurs » = 1, option « Fractionner » désactivée
- Sélectionner les simulations souhaitées dans la liste et lancer le calcul Batch
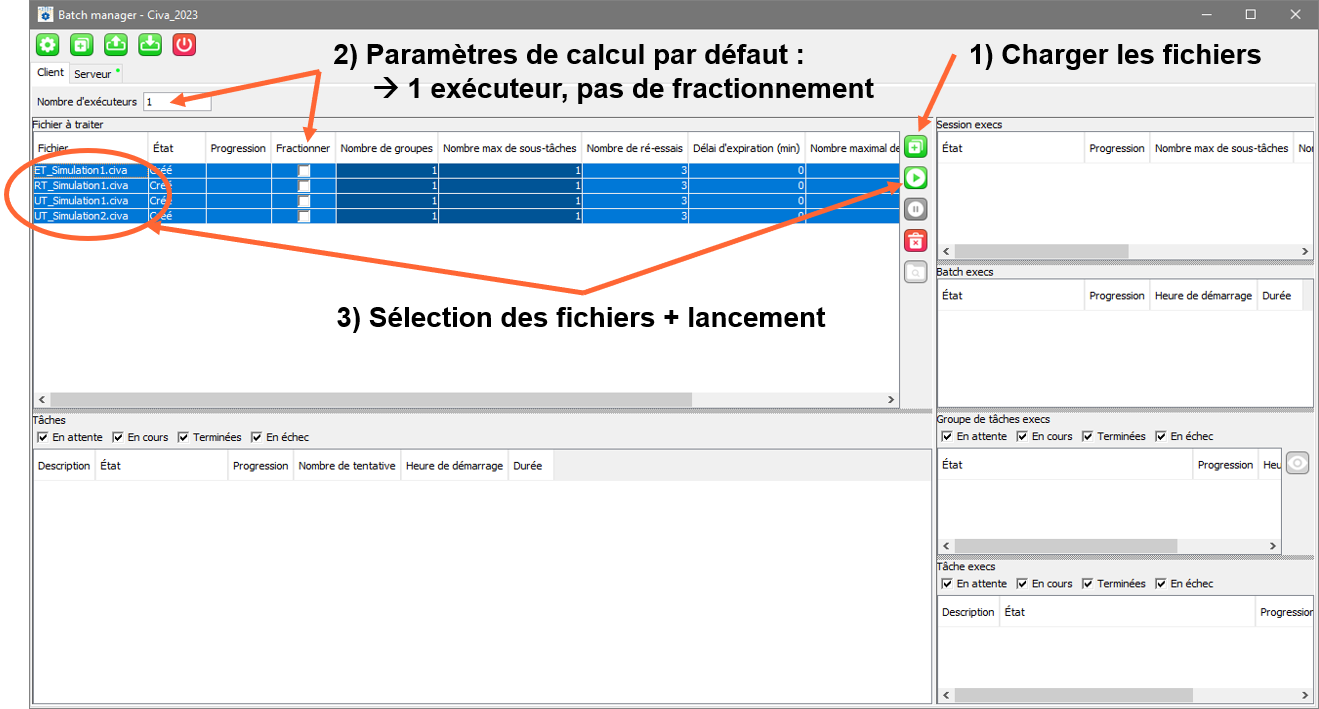
Paramétrage d’un calcul batch en mode « Traditionnel »
Remarque : Même lors de l’exécution d’un batch en mode traditionnel plusieurs cœurs de la machine peuvent être utilisés. Chaque simulation CIVA repose sur un algorithme spécifique avec un niveau de parallélisation donné dépendant de la technique et du type de calcul. Ainsi, lorsque l’algorithme utilisé est très bien parallélisé, les temps de calcul entre batch traditionnel vs parallélisé seront proches.
Mode parallélisé
La démarche pour définir un batch parallélisé est similaire à la méthodologie vue précédemment à l’exception qu’il faut cette fois-ci activer l’option « Fractionner » puis définir correctement les paramètres « Nombres d’exécuteurs », « Nombres de groupes » et « Nombres max de sous-tâches » (voir image ci-dessous).
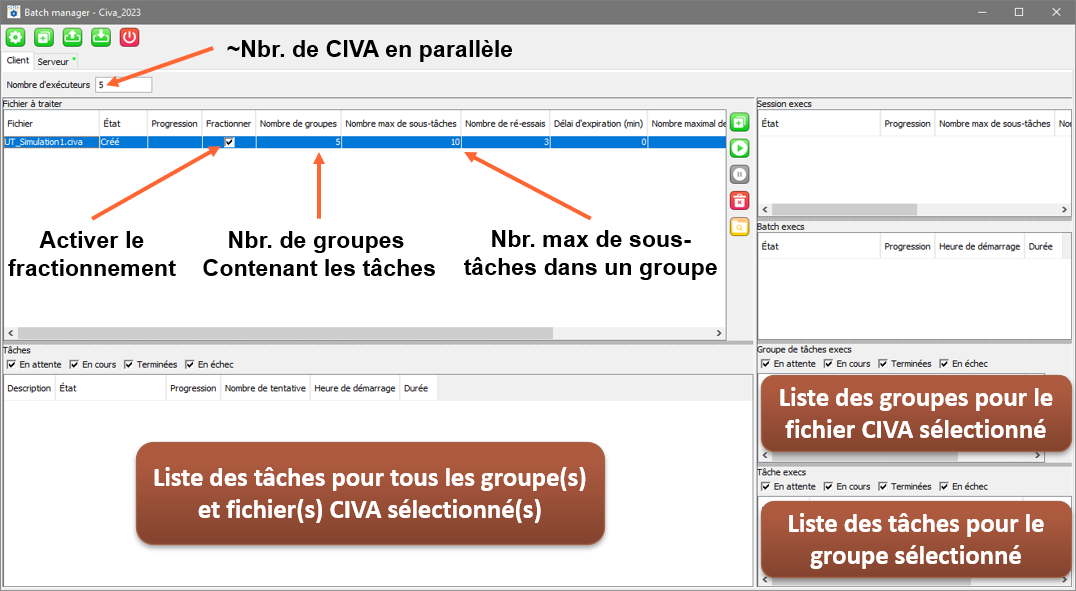
Paramétrage d’un calcul batch en mode « Parallélisé »
Globalement, un fichier CIVA peut être divisé en sous-tâches. Ces sous-tâches sont regroupées en groupes et ce sont ces derniers qui sont parallélisés lors du process de calcul batch. Le nombre d’exécuteurs peut être considéré comme le nombre d’instances CIVA ouvert en parallèle. Les groupes à traiter seront répartis sur le nombre d’exécuteurs défini.
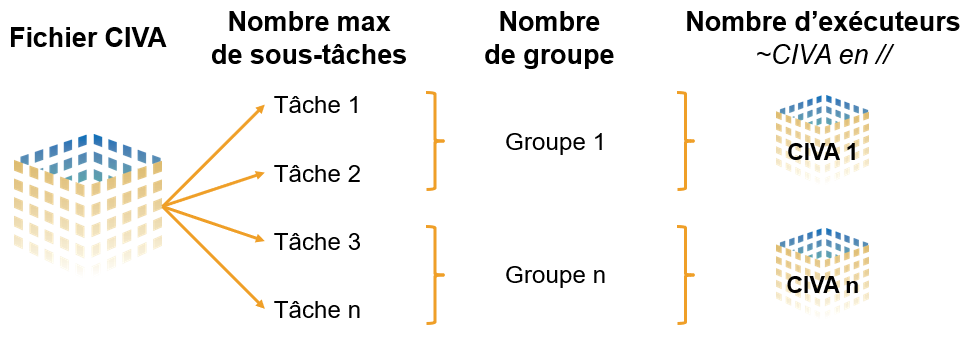
Principe de la parallélisation d’un fichier CIVA
Dans ce contexte, une tâche peut être :
- UT : un ensemble de positions, de séquence(s) et/ou de tir(s)
- CT : un ensemble de positions
- Etude paramétrique : le nombre de sous-tâches sera automatiquement défini comme étant le nombre de tirage(s) de la variation divisé par le nombre de groupe(s)
- Pour toutes les autres techniques, il n’est pas possible de fractionner la configuration CIVA en groupe ou en sous-tâche
Comme mentionné précédemment, l’efficacité de la parallélisation dépendra du niveau d’auto-parallélisation de l’algorithme impliqué dans le calcul.
La définition des paramètres de parallélisation est à faire manuellement et il n’existe pas de valeurs optimales et par défaut valables pour tous les cas car cela dépend très fortement de la configuration de machine utilisée et du type de calcul lancé.
Toutefois les bonnes pratiques suggérées sont de :
- Vérifier en amont l’activité du processeur avec un calcul en direct :
- Si l’activité du processeur varie beaucoup et qu’il ne fonctionne pas à 100%, la parallélisation batch pourra être efficace
- En revanche, si le processeur est stable et fonctionne déjà à 100%, l’apport de la parallélisation batch sera moins important
- Commencer avec un nombre d’exécuteur faible et l’augmenter petit à petit lors du calcul, cela permet de s’assurer que la mémoire RAM de la machine ne soit pas saturée