IA pour les END avec CIVA Data Science
Qu’est-ce que CIVA Data Science ?
Une réelle utilisation de l' »IA » dans les END souffrent de la difficulté de disposer de suffisamment de données pertinentes et explicites pour entrainer les algorithmes. La simulation peut surmonter cette situation en générant en masse des données pertinentes. Ce nouveau module CIVA Data Science permet de rassembler dans un environnement CND les simulations CIVA, l’analyse CIVA et des outils de gestion de données pour concevoir et valider des modèles de diagnostics basés sur de l’intelligence artificielle.
CIVA Data Science inclut les outils suivants :
- Bases de Données & Métamodèles : Collecter les données simulées et / ou expérimentales, définir le critère de sortie, adapter les critères d’intérêt via des scripts Python
- Fusion de Bases de Données : Fusionner différentes sources de données (différentes études paramétriques ou fichiers d’acquisition, données hybrides constituées d’images radiographiques expérimentales sans défaut augmentées de données simulées avec défauts, etc.) pour enrichir le nombre d’échantillons ou concaténer un critère d’analyse
- Notebooks Python : Utiliser des scripts et notebooks Python pour adapter les données à vos besoins
- Classification : Définir les classes de défauts, entrainer et paramétrer les modèles de classification puis les évaluer sur une base de données externe
- Détection : Entrainer le modèle sur une classe et régler le seuil pour une évaluation de type « Succès / Echec »
- Analyse Prédiction : Evaluer la précision des métamodèles que vous avez générés à partir de vos bases de données et des variations paramétriques
Avec Bases de Données & Métamodèles, importez les différents jeux de données (expérimentaux et/ou simulations).
CIVA Data Science peut charger des fichiers de variation CIVA (*.var), des données expérimentales exportées depuis CIVA Analyse au format *.cck via la fonctionnalité export « DS », mais aussi des fichiers *.txt ou *.csv.
Ensuite, définir et visualiser le critère de sortie sur lequel les algorithmes d’apprentissage automatique et de réseaux de neurones vont travailler pour classer les données. Des métamodèles peuvent être générés pour accroitre la taille des échantillons. Des outils permettent de vérifier la cohérence des données (en termes de critères de sortie, de labels, de dimensions des données, etc.) afin de s’assurer que l’apprentissage puisse être opérationnel.
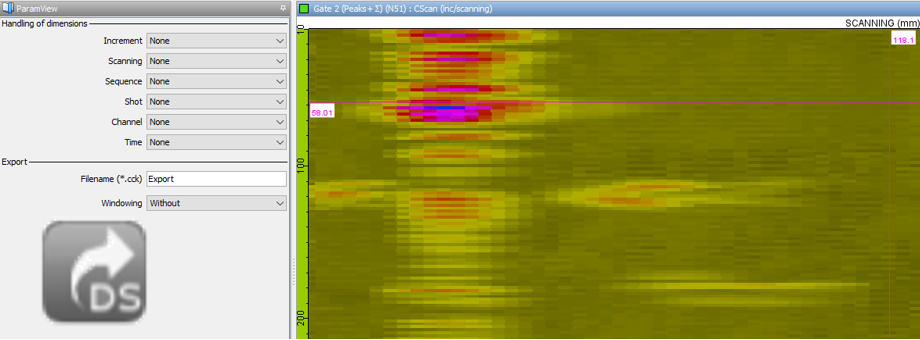
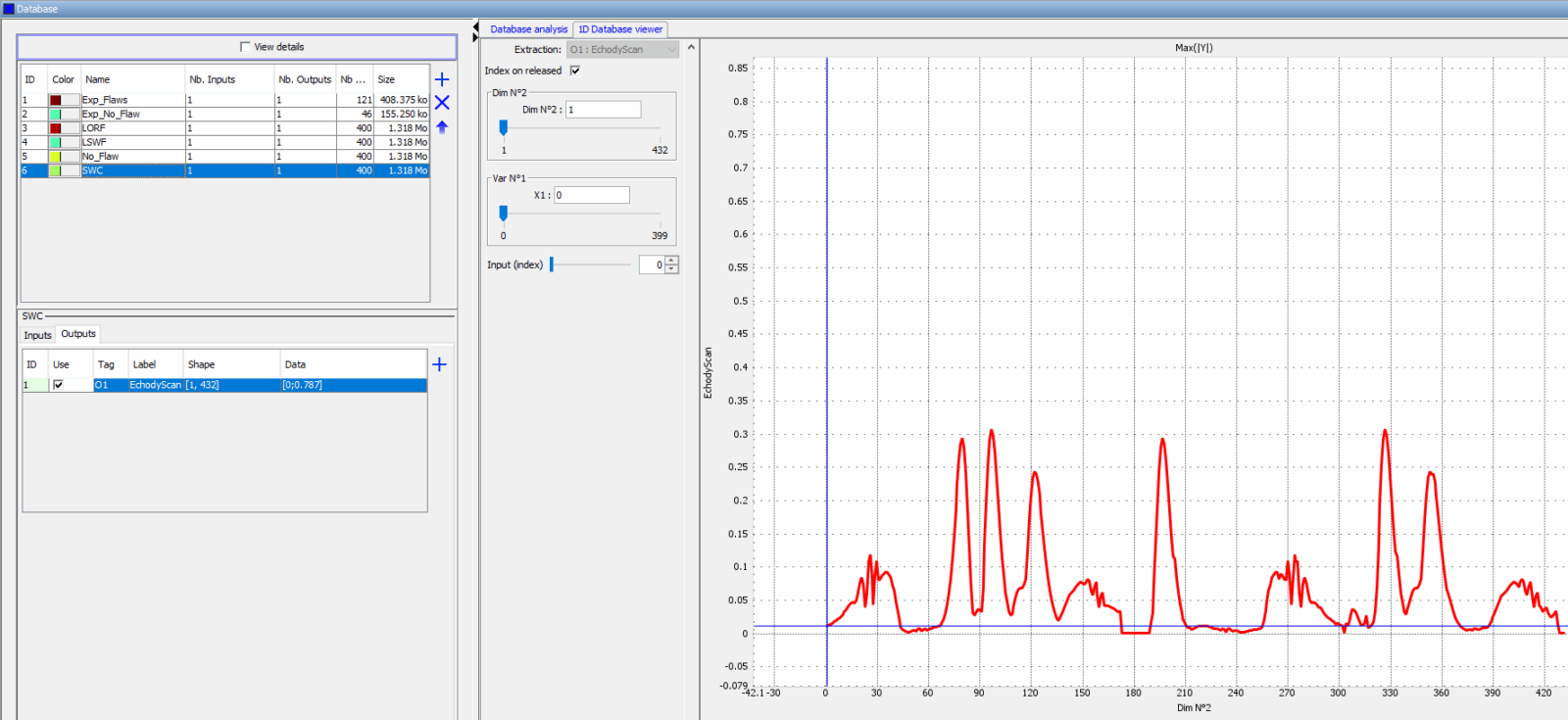
Définir un critère d’analyse pertinent peut nécessiter de fusionner ou transformer les données brutes depuis différentes sources.
C’est le rôle des outils Fusion de Bases de Données et Notebooks Python. Un script Python peut être directement défini dans cet environnement à cette fin. Des scripts Python peuvent aussi être nécessaires pour extraire une quantité pertinente des simulations paramétriques CIVA. C’est pourquoi CIVA Script est inclus dans le module CIVA Data Science.
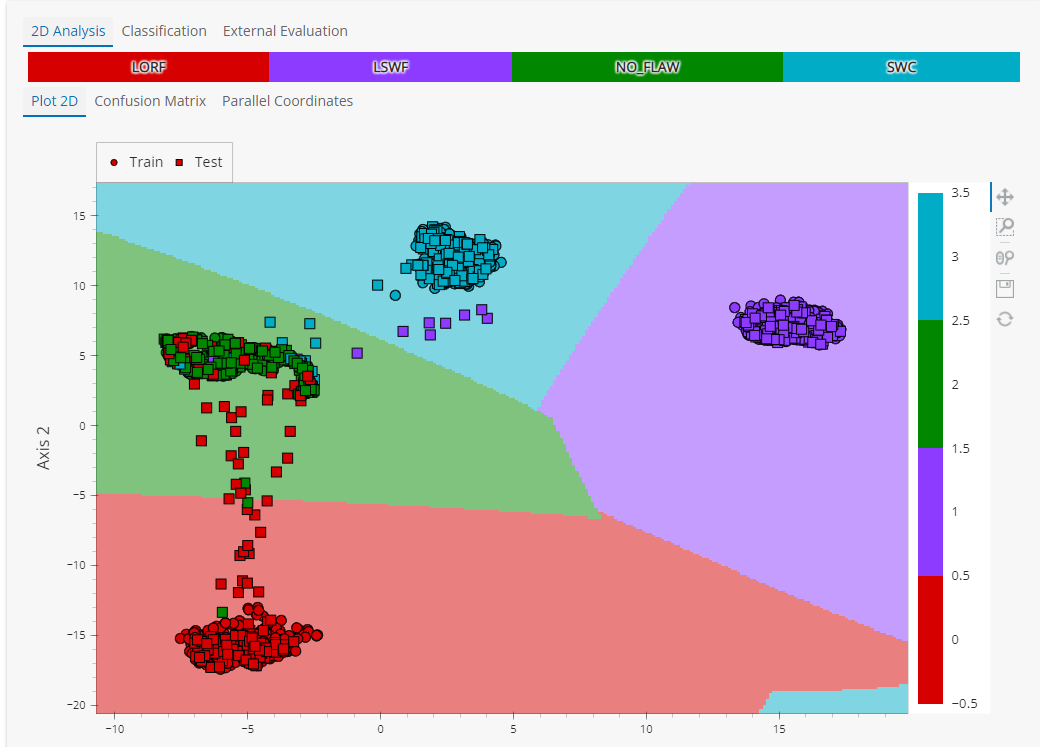
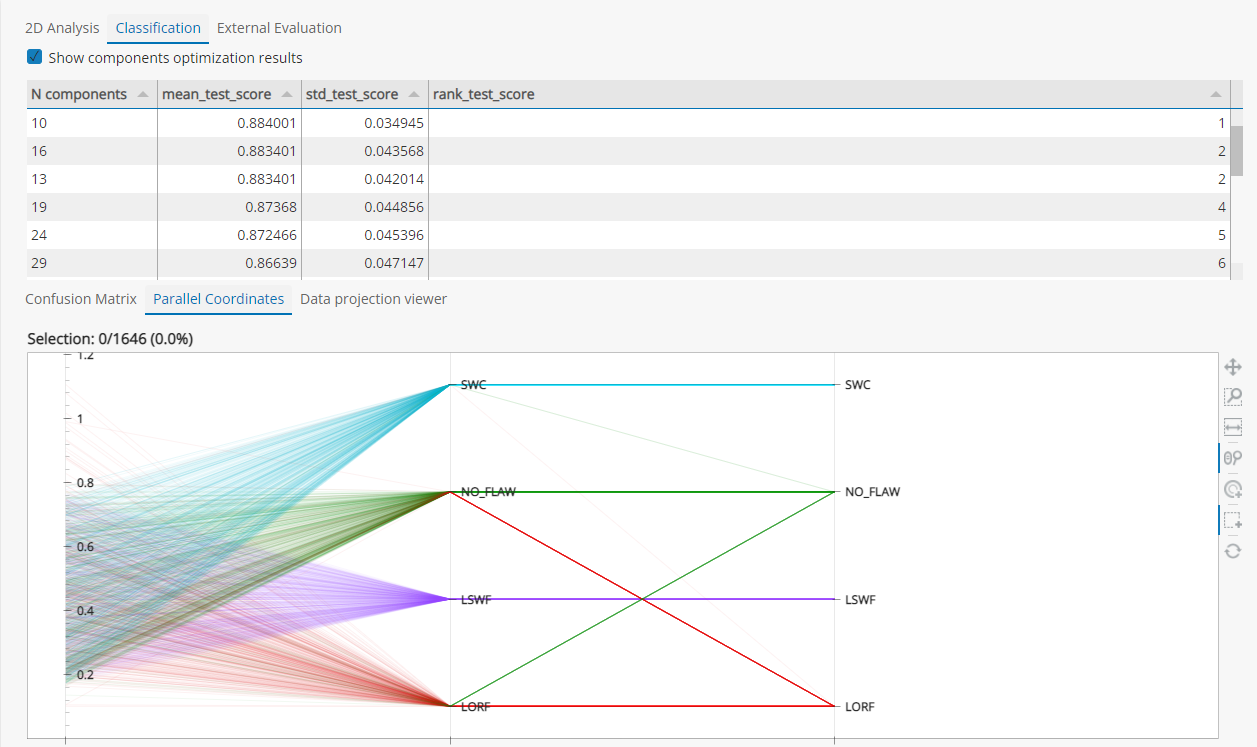
Une fois les données collectées et organisées, vous pouvez entrainer des outils de classification pour développer un modèle d’aide au diagnostic. Le but est de détecter et caractériser automatiquement des signaux de défauts à partir de données END. Le module de Classification permet de définir les classes ciblées, pré-analyser rapidement la capacité à séparer les données de façon pertinente à partir du critère de sorti choisi, puis de comparer et régler différents algorithmes de normalisation, projection et classifieurs et leurs paramètres pour entrainer vos données.
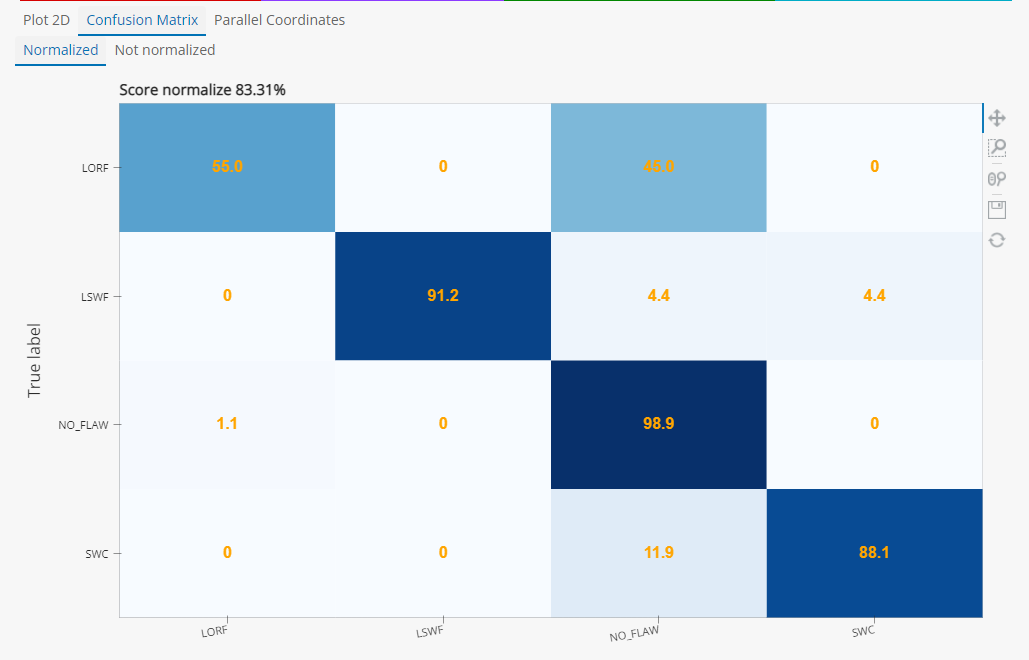
CIVA Data Science inclut des graphiques de visualisation tels que des diagrammes 2D, des diagrammes parallèles ou des matrices de confusion pour régler les paramètres d’entrainement.
Finalement, évaluer le modèle de diagnostic sur un jeu de données tiers.
Un autre module Détection permet d’entrainer le modèle sur une classe et de régler le seuil pour une évaluation de type « Succès / Echec », par exemple « Défaut / Zone saine ».