
SuperBatch
The Batch Manager has evolved since CIVA 2023. However, the final objective remains the same: to launch a series of predefined simulations based on any of the techniques available in CIVA. The main reasons for using the Batch Manager are as follows:
- No need to run calculations manually, one by one
- Reduce calculation times by making better use of multi-core machines and parallelizing calculations
- Simulations can be added to an already running batch at any time
- In the event of unexpected interruption of a calculation in parallelization mode, all tasks performed are automatically saved and do not need to be recalculated
There are two ways to use the Batch Manager and perform the calculations:
- “Traditional” mode: no parallelization, CIVA files are calculated one by one according to the defined list of simulations
- “Parallelized” mode: CIVA files and task groups are calculated in parallel
Traditional mode
There are three stages in defining a batch calculation in traditional mode (see the image below):
- Load the predefined simulations to be processed
- Keep default calculation parameters: “Number of executors” = 1, “Splitting” option disabled
- Select the desired simulations from the list and run the batch calculation
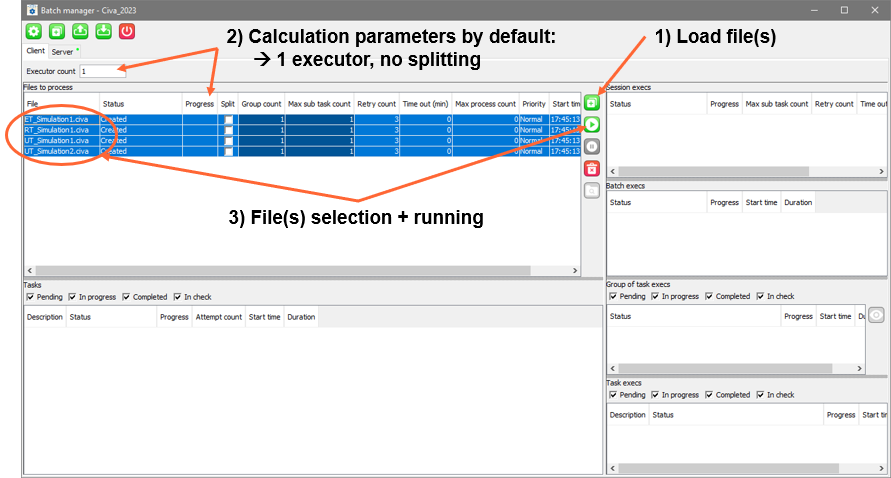
Traditional batch mode setting
Note: Even when running a batch in traditional mode, several cores of the machine can be used. Each CIVA simulation is based on a specific algorithm with a given level of parallelization depending on the technique and type of calculation. Thus, when the algorithm used is already efficiently parallelized, calculation times between traditional and parallelized batches will be close.
Parallelized mode
The procedure for defining a parallelized batch is similar to the one described above, except that this time you need to activate the “Splitting” option and then correctly define the “Number of executors”, “Number of groups” and “Maximum number of sub-tasks” parameters (see the image below).
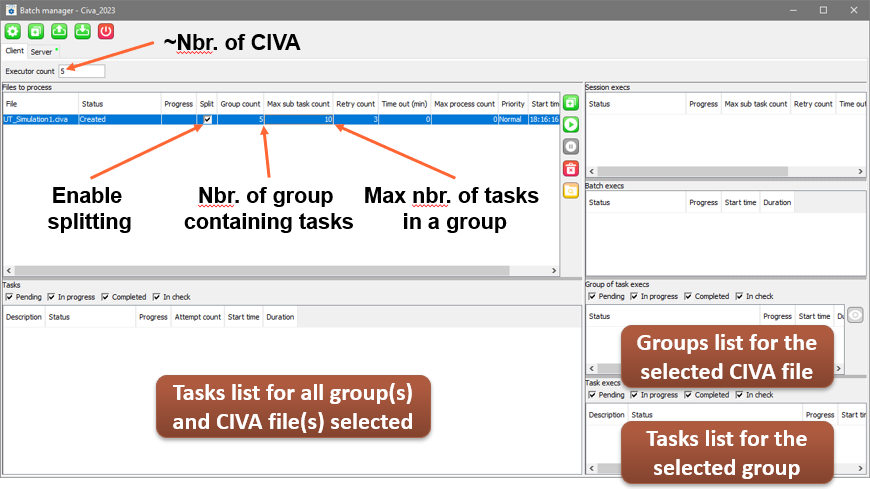
Parallelized mode setting
Generally speaking, a CIVA file can be divided into sub-tasks. These sub-tasks are grouped together into clusters, and these clusters are parallelized in the batch process. The number of executors can be thought of as the number of CIVA instances open in parallel. The groups to be processed will be distributed over the defined number of executors.
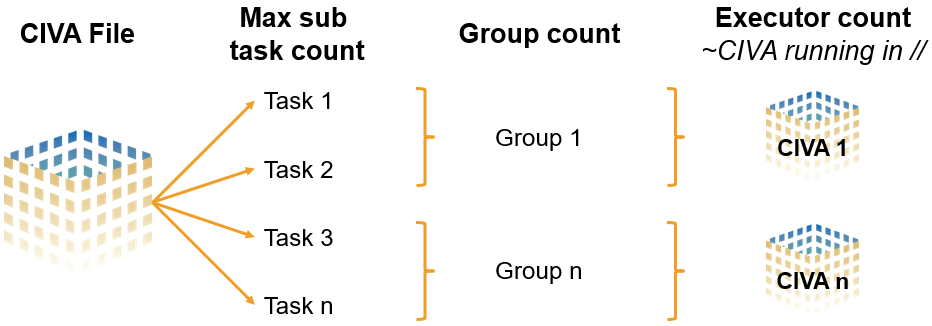
Parallelization principle of a CIVA file
In this context, a task can be:
- UT: a set of position(s), sequence(s) and/or shot(s)
- CT: a set of position(s)
- Parametric study: the number of sub-tasks will be automatically defined as the number of variation runs divided by the number of group(s)
- For all other techniques, it is not possible to split the CIVA configuration into groups or sub-tasks
As mentioned previously, the efficiency of parallelization will depend on the level of auto-parallelization of the algorithm involved in the calculation.
Parallelization parameters have to be defined manually, and there are no optimal default values that are valid for all cases, as this depends very much on the machine configuration used and the type of calculation launched.
However, suggested best practices include to:
- Check processor activity during a direct calculation:
- If processor activity varies greatly and the processor is not running at 100%, batch parallelization can be effective
- On the other hand, if the processor is stable and already running at 100%, the contribution of batch parallelization will be less significant
- Start with a low number of executors and gradually increase it during the calculation, to ensure that the machine’s RAM is not saturated