AI for NDE with CIVA Data Science
What is CIVA Data Science?
Real use of “AI” in NDE suffers from the difficulty of getting sufficient and relevant data to train algorithms. Simulation can overcome this situation by efficiently providing massive and relevant data sets. This new CIVA Data Science module allows you to bring together CIVA simulations, CIVA Analysis, and data management tools to design and validate AI-based diagnostic models in an NDE environment.
CIVA Data Science includes the following tools:
- Databases & Metamodels: Collect simulated and / or experimental data, define output criteria, customize output criteria with Python Scripts
- Databases Fusion: Merge different data sources (different parametric studies or acquisition data files, hybrid data between experimental RT images without flaw and RT simulations with flaws, etc.) to increase the number of samples or stack the criterion
- Python Notebooks: Use Python script and notebooks to customize or adapt data sets to your needs
- Classification: Define defect classes, Train and set automatic classification models then evaluate them on an external database
- Outlier Detection: Train the model with one class and set the threshold for success / fail evaluation
- Prediction Accuracy: Evaluate the accuracy of the metamodels you generated from the databases and simulation variations
With Databases & Metamodels, import different data sets (experimental data or simulation data).
CIVA Data Science can load CIVA variation files (*.var), experimental data exported from CIVA Analysis in *.cck format with the “DS” export feature, but also *.txt or *.csv data files.
Then, define and visualize the output criterion on which the machine learning or Neural Network algorithms will work to classify the data. Metamodels can be generated to increase data set sizes. Tools allow to check the data consistency (output criteria, label names, data dimensions, etc.) to make sure AI will be operational.
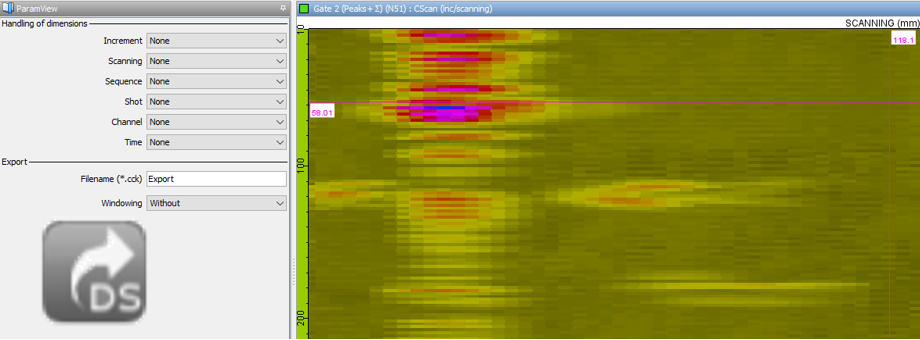
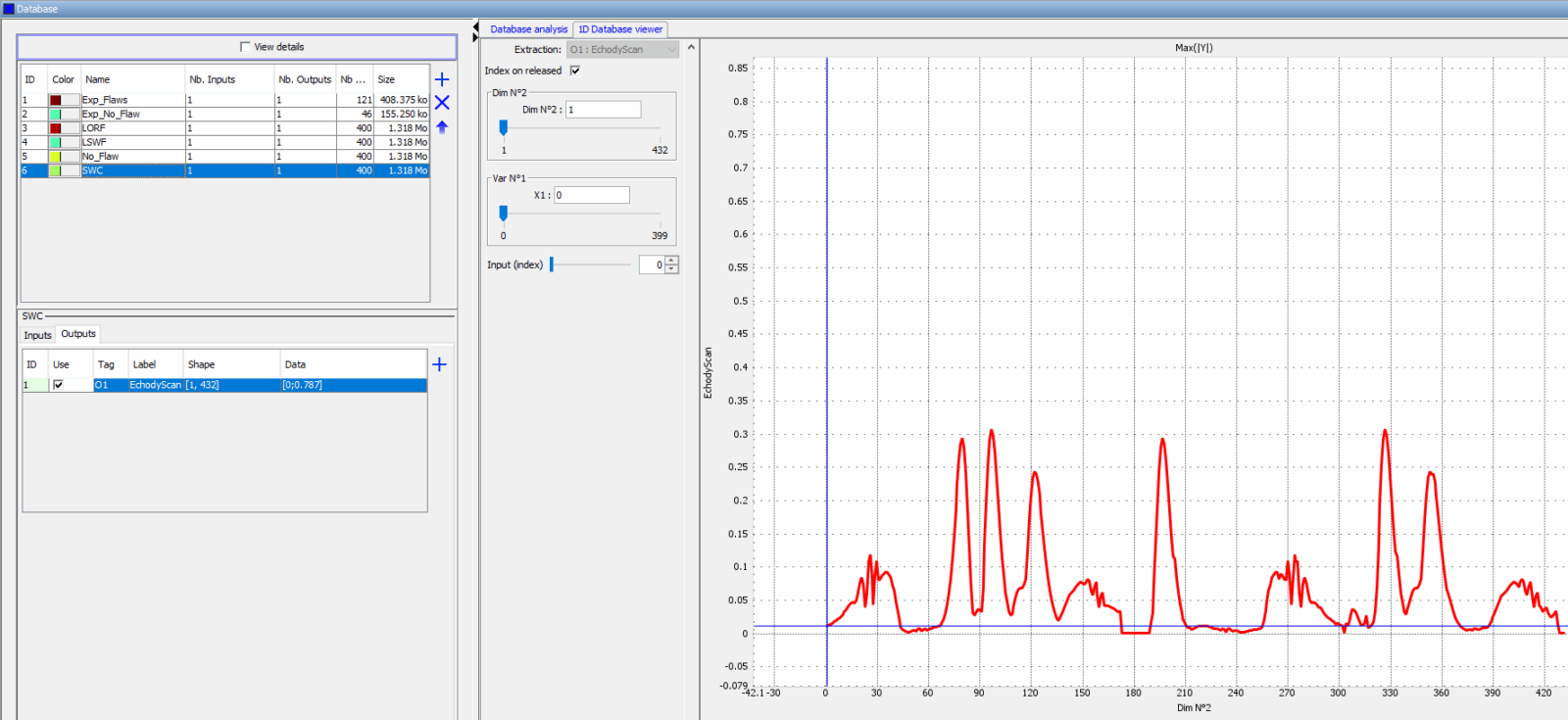
To define a relevant output criterion might need to merge or transform raw data from different sources.
This is the role of the Databases Fusion and Python Notebooks tools. Python script can be defined within this environment for that purpose. Python scripts can be also used to get the relevant outcomes from CIVA parametric simulations. This is why the CIVA Script module comes with CIVA Data Science.
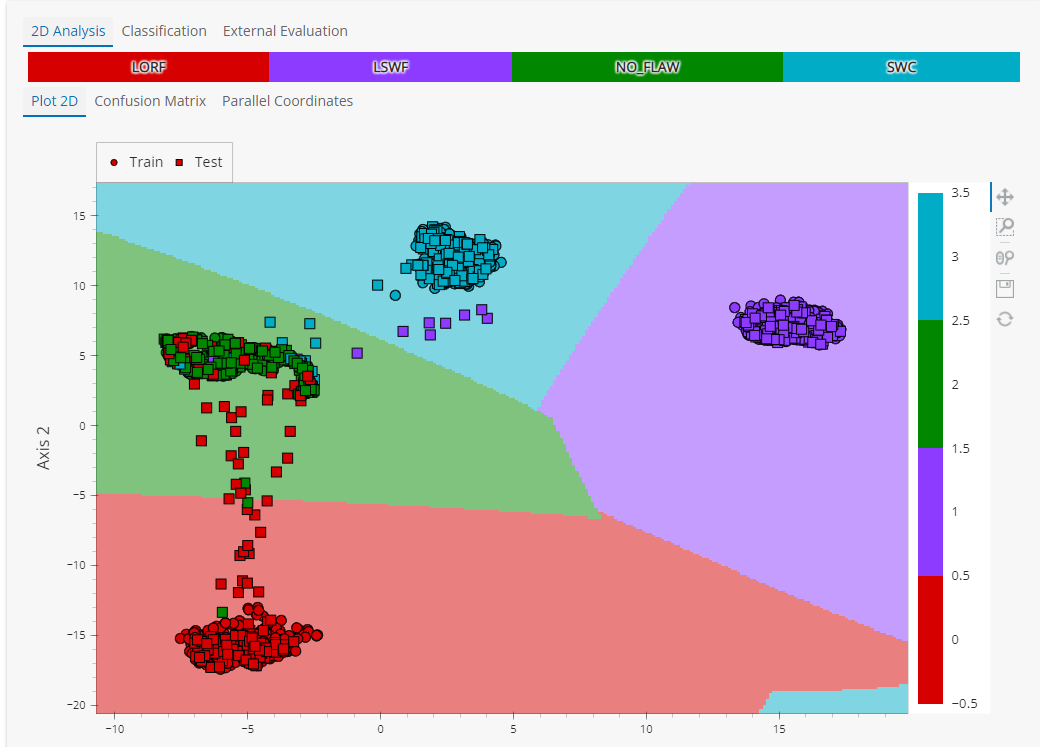
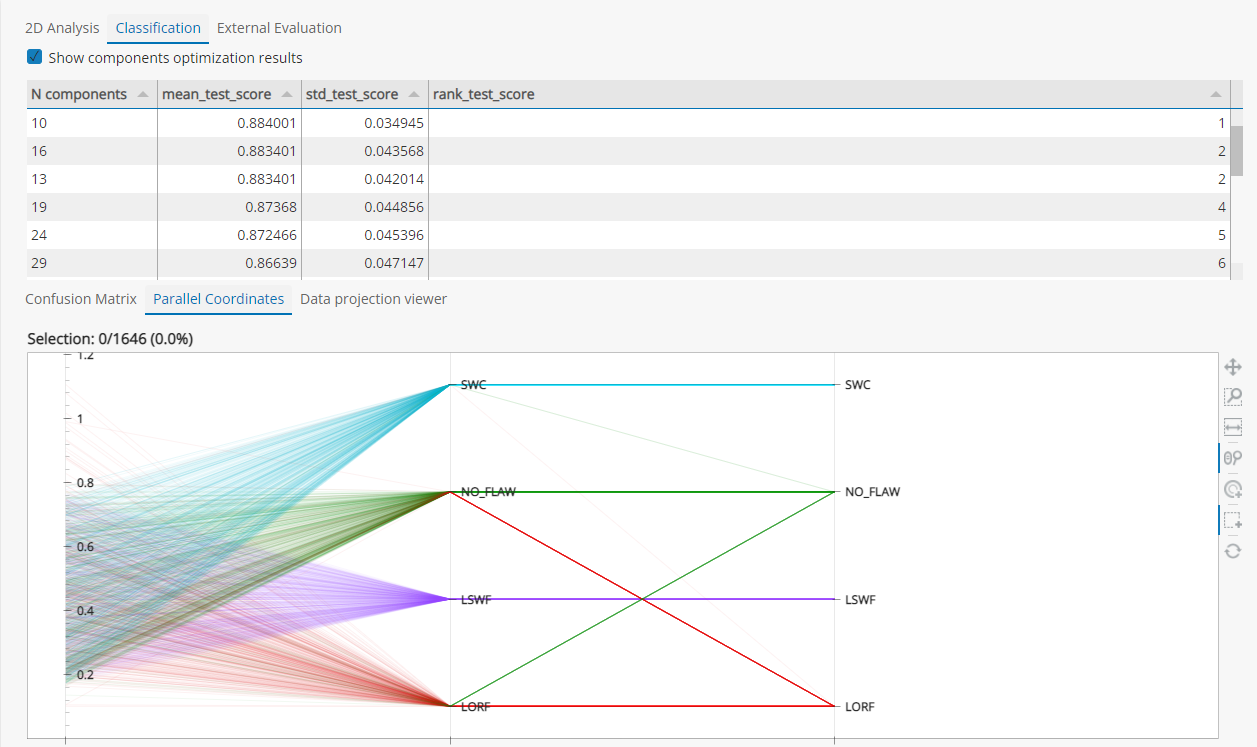
Once data are collected and organized, you can train machine learning based classification tools to develop an aided-diagnostics model. The purpose is to automatically characterize and detect flaw signals on NDE data. The Classification module will let you define the relevant classes, quickly pre-analyze the ability to split data in a relevant way with your output criterion, then compare and set different Scaler, Projection, and Classifier algorithms and parameters to train your data.
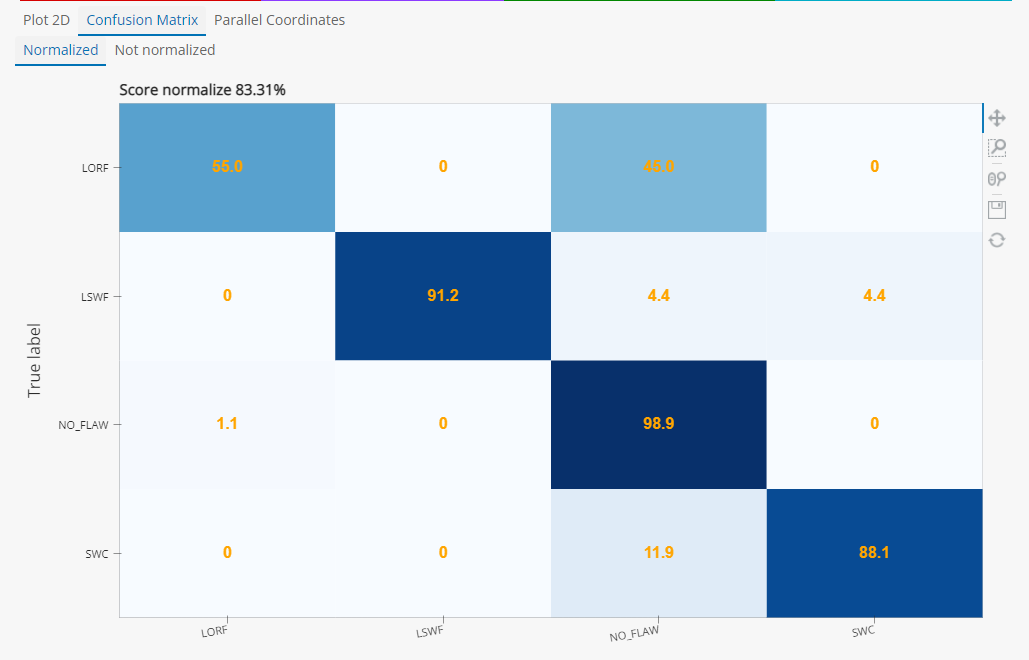
CIVA Data Science includes visualization maps and graphs such as 2D plots, parallel plots, and confusion matrices to set up and check training parameters.
Finally, evaluate the diagnostic model on an external data set.
Another module Outlier Detection allows you to train a detection model for one class success / fail evaluation. It can be for instance flaw / no flaw detection by training it on no flaw databases.